
The New Steamroller CPU Cores
For the CPU in Kaveri, AMD is sticking to the x86 Bulldozer architecture. Chips will feature either one or two modules (and thus two or four cores), and each module has its own fetch and decode hardware, the two main integer cores, a single shared floating point core and a shared L2 cache of up to 2MB. However, Kaveri's cores are actually the third generation of the Bulldozer architecture, known as Steamroller, so while the layout remains the same as that in the Piledriver cores of Richland and Trinity, there have still been a host of improvements worth discussing. It's also worth noting that AMD is committed to Bulldozer beyond Steamroller, as a fourth iteration (Excavator) is also planned (plans for Cement Mixer are yet to be outlined - Ed.).Clock for clock, AMD says that the Steamroller cores are up to 20 percent faster (about 10 percent on average) than the previous generation. However, the move to a 28nm process means the chips are more limited in their clock speeds. Therefore, performance is unlikely to improve massively in pure x86 applications, something which even AMD admits. The emphasis of Kaveri is more about increasing performance per watt.
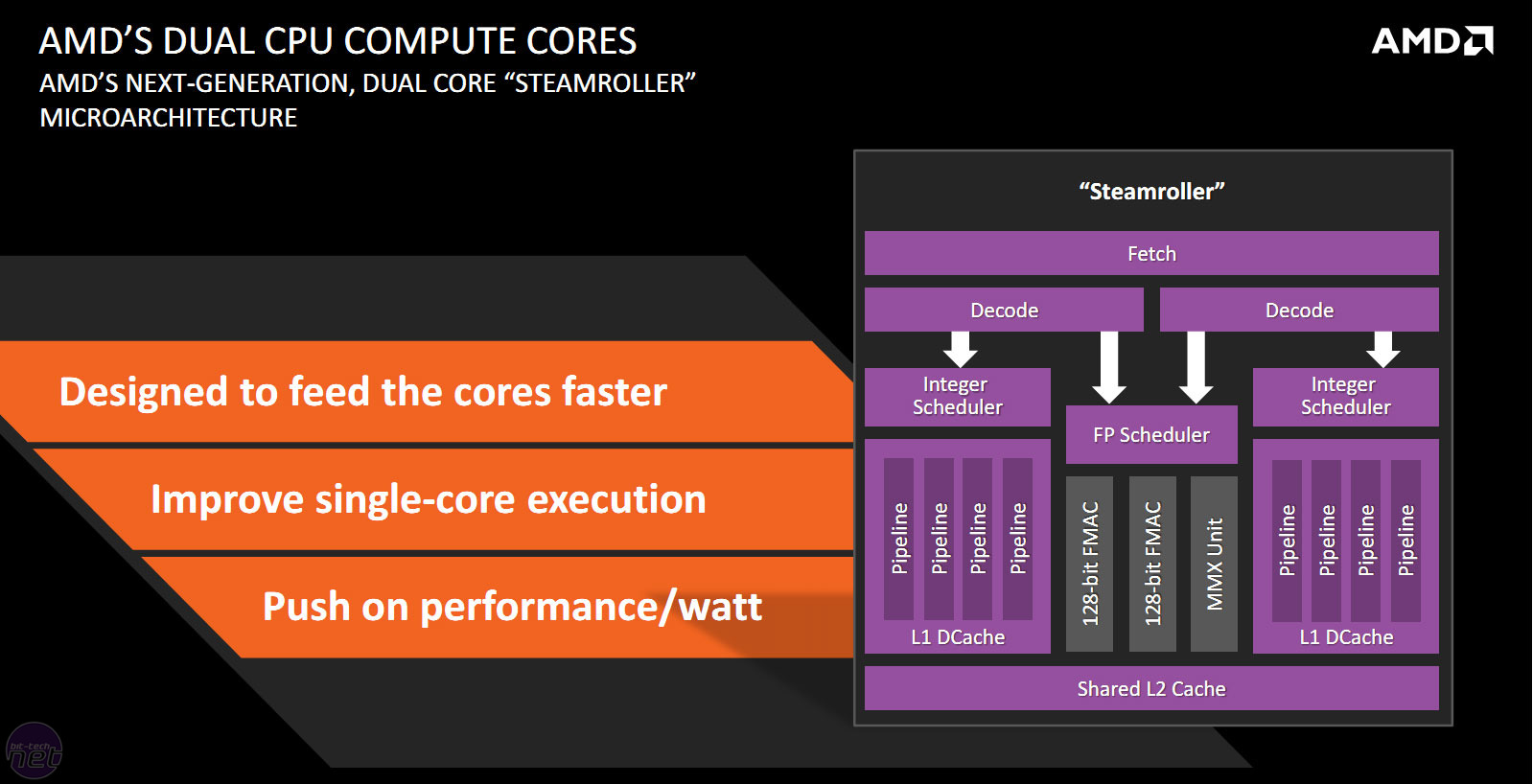
Click to enlarge - The updated high level layout of the Steamroller modules
Kaveri's biggest upgrade is found at the front end, where AMD has doubled the decode hardware such that each of the two cores in a module is now fed by its own independent decoder. Previously, a module could decode up to four instructions from a single thread at once, and switch between threads every clock cycle. With the new design, however, the separate decoders can work on two different threads in parallel. As ever, the benefits of this depend massively on the current workload, but it's certainly the change that paves the way for improved performance more than any other.
The size of the L1 instruction cache has also been increased from 64KB to 96KB. AMD claims that this results in I-cache misses being reduced by up to 30 percent, which in turn means less time wasted by having to access higher-latency system memory instead.
Kaveri inherits the improvements to branch prediction hardware that the Piledriver cores features, but its Steamroller cores comes with its own improvements here too. One such improvement is a larger branch target buffer, which contributes to Steamroller's lower rate of misdirected branches (as much as 20 percent).
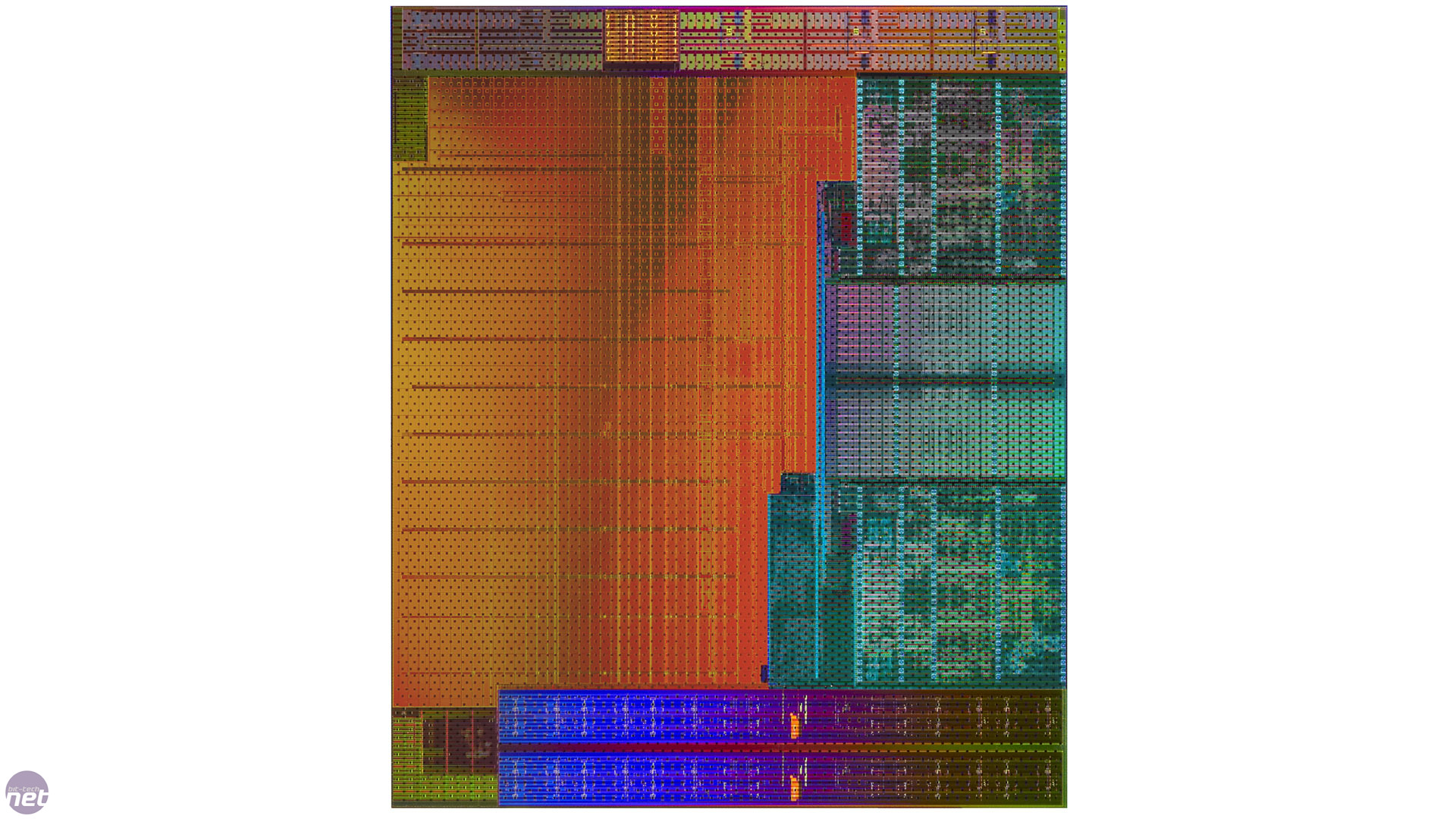
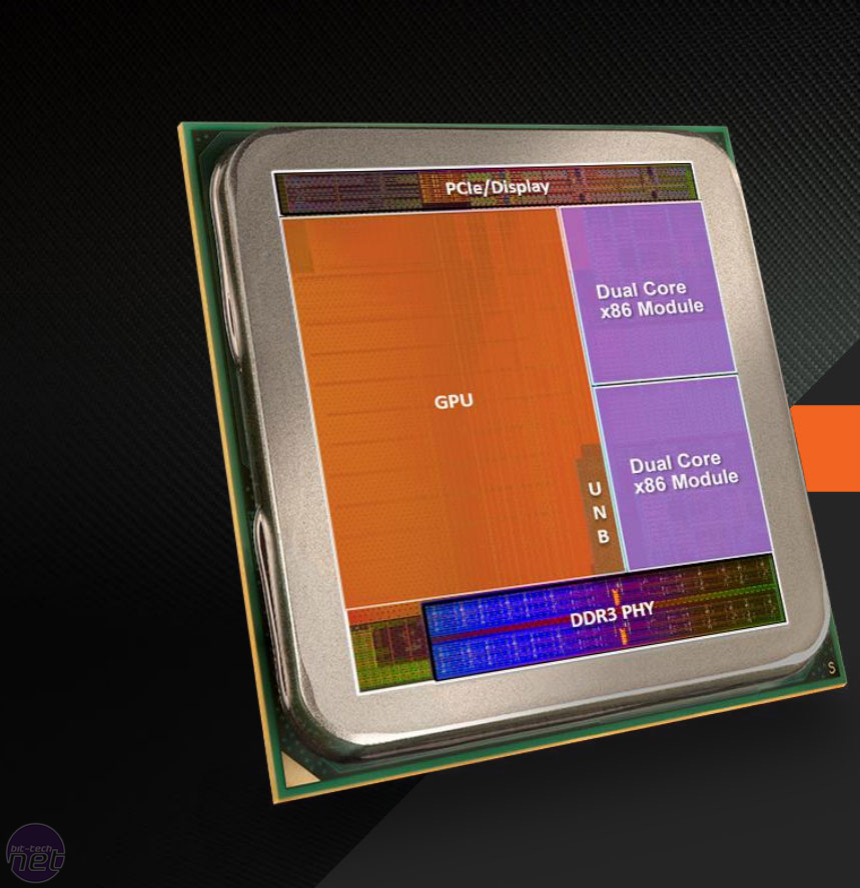
Click to enlarge - A die shot of Kaveri and an overlay showing its layout
Other small local caches and buffers within the CPU hardware have also seen size increases. However, larger caches and more decode hardware results in increased power draw (not to mention die size). To counter this, AMD has had to tighten its belt elsewhere.
The shared FP core, which can be fed by both decoders, has been streamlined so that it now has a shorter and more efficient pipeline. According to AMD, its performance should largely be unaffected, even though it now consumes less power and occupies less space.
AMD has also made power optimisations at the front end, as well as in the 2MB of L2 cache that each module shares between its cores. If it's not all being used at any given time, parts of this cache can now be powered down. Power savings of this sort are obviously more beneficial to notebooks and battery powered devices, but are nevertheless still important in keeping the chip within its power and thermal limits.
Finally, single core execution has been boosted with various minor tweaks and enhancements to the cores, specifically scheduling efficiency and store handling within the L1 cache.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.