
What’s a Module, what's a Core?

A Bulldozer Module contains two cores
After all, a Bulldozer ‘core’ isn’t as capable as a Phenom II core, for example, as each Phenom II core can fetch and decode work and doesn’t have to share its floating point capabilities with anything else.
We asked Bernard Seite, technical advisor, AMD, whether we really should regard the two execution units within a Bulldozer Module as cores and were told, ‘If you take the overall group of applications that are running on x86, 90 per cent is integer… We look at how efficient Hyper-Threading [is]. Sometimes you have negative impact, but most of the time, you have something which is in between zero and 40. The Bulldozer Module will never be negative [in its performance gains] – you have two threads, and the two threads are not going to clash.’
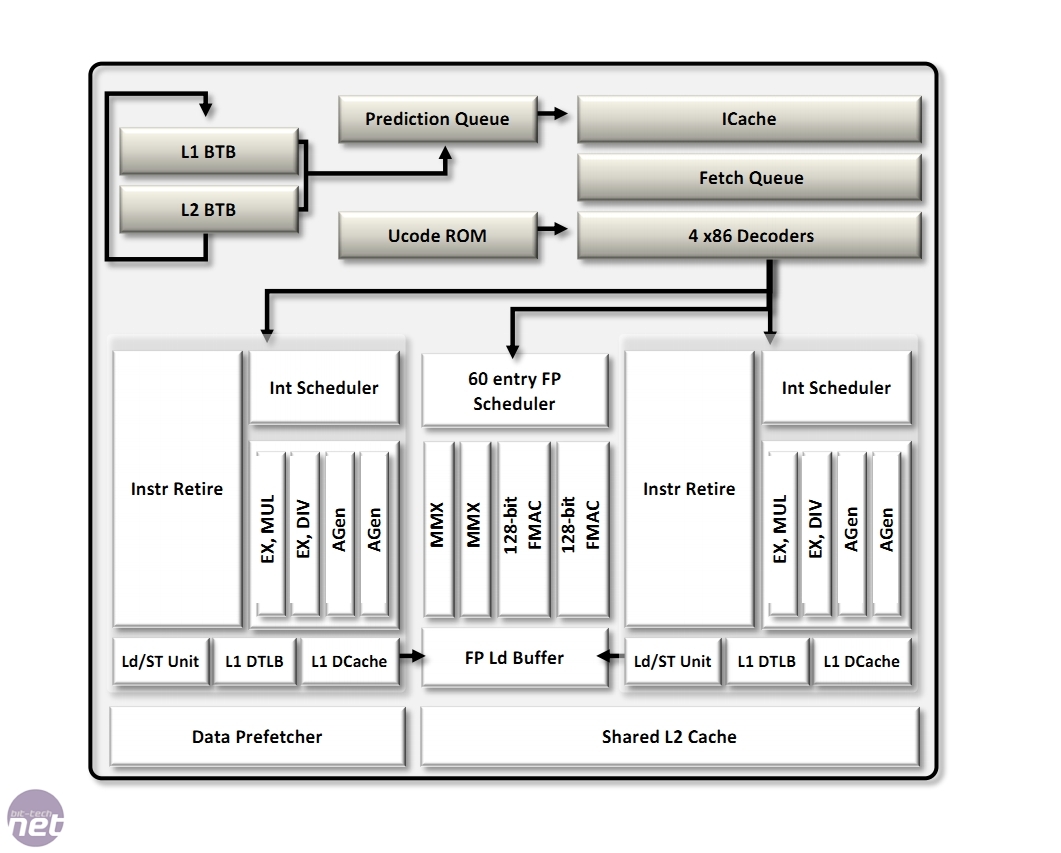
Seite did admit that the two execution cores within a Bulldozer module shared more than the floating point unit (the FMAC Scheduler and the unit itself that’s split into two 128-bit halves): ‘ we’re sharing the front end, the Level 2 cache – and there could [theoretically] be conflicts of course, because we have two cores.’ But the Level 2 cache is a healthy 2MB in size to compensate: ‘To avoid conflicts (in L2), we change the associativity, we change also the size… By having different types of associativity – more ways in the associativity – by having a bigger cache – you are avoiding this problem. [You’re] compensating for the sharing.’
Seite also confirmed that as part of the decoupling of the Fetch and Decode units in the front-end of a Bulldozer module (an innovation over previous designs), the front-end unit can accept two threads of work simultaneously and conduct simultaneous sequencing of these threads.
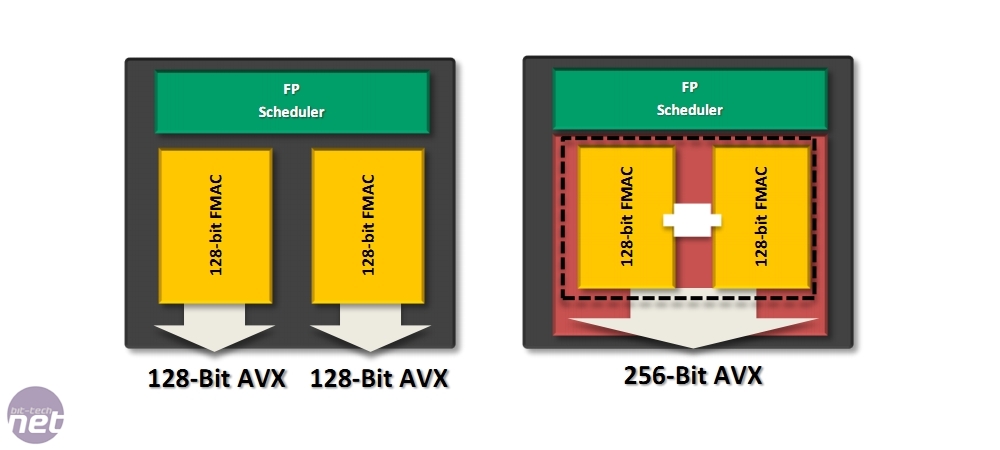
The two 128-bit FMAC units can work independently if the Module is porcessing two
threads that require 128-bit precision, or can be ganged if a 256-bit fp precision
threads comes along
The only time two threads within a Bulldozer Module could clash, we were told, was if each required 256-bit floating point precision, for example if both threads used the new 256-bit AVX capabilities of the CPU. This is because the floating point unit – as previously alluded to – is shared and comprises two 128-bit fp units which can be ganged to produce a single 256-bit unit. However, it’s very unlikely that we’ll see many 256-bit fp threads any time soon as the standard is new and will take time to adopt. Seite also pointed out that ideally the OS (or the complier, potentially) should be aware of the capabilities of the Module and assign the second 256-bit thread to another Module, perferrably one not running any hardcore fp work.
This ties in with AMD’s mantra that Bulldozer is a forward-looking architecture. It’s working with Microsoft at the moment to improve thread scheduling with Bulldozer CPUs in Windows 8 for a 2-10 per cent performance boost. It gave the following example:
The Module front-end has seen big improvements over previous AMD CPU front-end units
Given all this, we’ll relax our attitude toward Bulldozer’s core count and agree with AMD that it’s an 8-core CPU. Alas, the ability to disable individual cores within a Module is absent from current BIOSes, so there’s no definitive way to test some of the claims AMD makes, but we’re humble enough to admit we were too sceptical when we first heard the term.
Keen-eyed readers will also notice that there are four integer pipelines within each Bulldozer core, a significant move from AMD as it allows greater parallelism when dealing with tasks. It’s a move Intel made with its Conroe design in July 2006 to much success. Going four pipes wide should give Bulldozer CPUs some much-needed IPC grunt.
AMD has also caught up with Intel’s support of AESNI encryption, SSE 4.1 and 4.2 instruction sets, while also adding new instructions in the form of FMA4 and XOP. These are useful for high-performance computing (HPC) in the case of FMA4 and ‘numeric applications, multimedia applications and algorithms used for audio/radio’ in the case of the latter. Software will need to be compiled using a compiler that’s aware of these extensions, with AMD citing the open source Open64 v4.2.5.2 compiler as an example.
AMD also added that, ‘the AMD FX processor, with its radical new design, represents a new way of processing that can be limited in previously compiled applications and OSes. It is important to optimise data loads into the processor and this requires an update to the compilers generating code for the processor and an update to the Operating System Scheduler.’ It also said that Microsoft Visual Studio 2010 SP1 supports XOP, FMA4 and SSE 4.x – it’s a popular development environment, so perhaps we won’t have to wait too long before seeing applications that use the extra extensions and instruction sets in Bulldozer CPUs.







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.