
Advanced Smart Cache:
Each Wolfdale die has up to 6MB of shared L2 cache which works in much the same way as Conroe’s shared L2 cache while a Yorkfield processor can feature up to 12MB of L2 cache. This is split into two 6MB chunks and coherency traffic between the two caches is still (inefficiently) passed via the memory controller hub (the northbridge) over the front side bus like it was with Kentsfield.The Core 2 Extreme QX9650 has all 12MB of L2 cache enabled, which makes sense considering this will be Intel’s flagship desktop processor until it releases something at a higher frequency. With some of the more mainstream-orientated quad-core processors, it’s possible that the cache size may be reduced to 6MB (one 3MB shared L2 cache per die)
Along with the 50 percent increase in cache size, Intel has also improved the L2 cache associativity by 50 percent – while Conroe had a 16-way set associative L2 cache, Wolfdale’s 6MB L2 cache has 24-way associativity. The increased cache associativity essentially means there are more inputs and outputs into the cache – this goes a way to help maximise utilisation of the larger L2 caches.

Smart Memory Access:
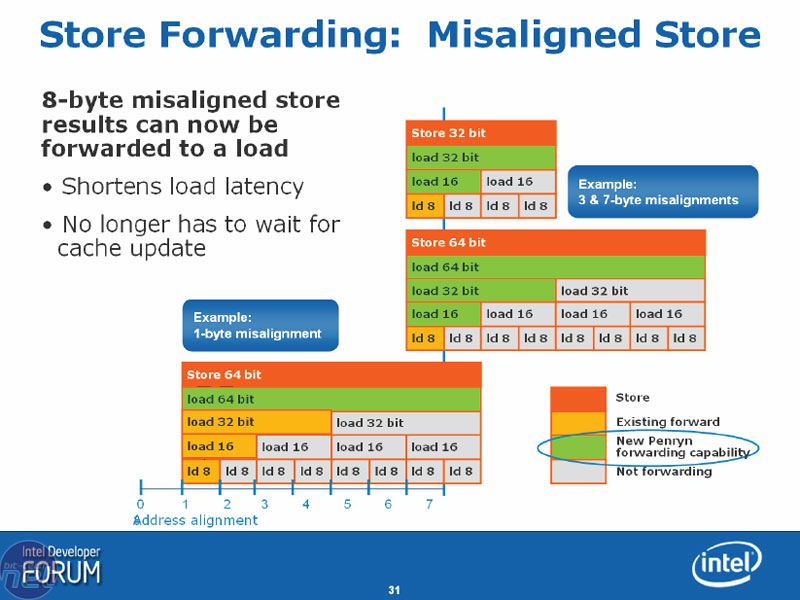
This employs smart prefetching algorithms to increase the processor's efficiency by enabling the chip to intelligently re-order instructions to reduce execution time in respect to load - Intel calls this Memory Disambiguation. The algorithm makes an educated guess about whether or not the chip can move on to the next set of instructions. The Memory Order Buffer is directly responsible for this element of the Core architecture. It works to "hide" the latency inherent in a separate northbridge and front side bus design.Latency hiding has been further enhanced through an improved Store Forwarding algorithm which essentially speeds up the reading of the result of a misaligned store by forwarding the result of the store to the load immediately, instead of waiting for the store to finish and write to memory. The Penryn family of processors builds on the existing misaligned store functionality to include the complete set of basic three and seven byte misalignments as well as 64-bit one byte misalignments. However, other core algorithms and prefetchers remain unchanged.
Advanced Digital Media Boost:
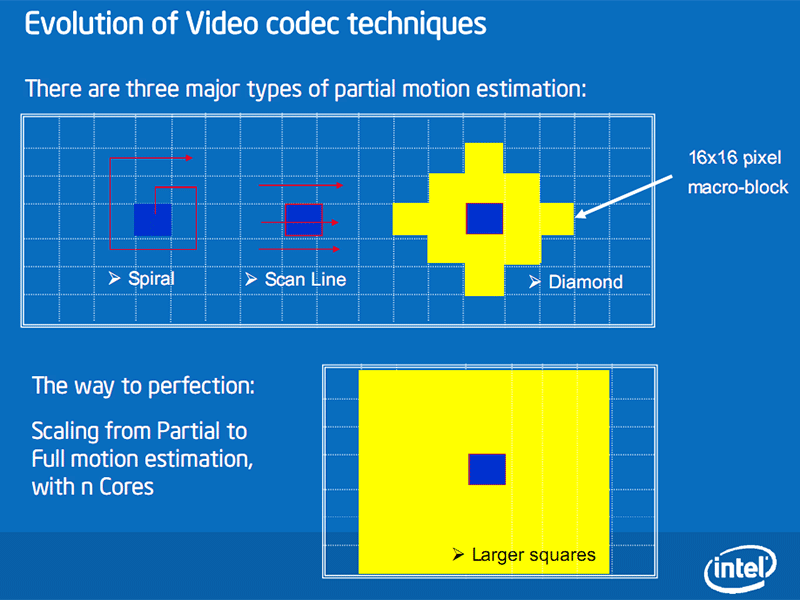
Probably the biggest change to the architecture is the introduction of SSE4.1, which adds 49 new instructions. SSE4.1 represents the largest set of new instructions introduced since the year 2000 when Intel added 144 new instructions (known collectively as SSE2) to the Pentium 4. The focus of these new instructions is to further improve performance in SIMD (single instruction multiple data) software and they’re focused around three key components – video acceleration, graphics building blocks and streaming load.Two new instructions that Intel has talked about quite a bit are Fast Block Difference and Horizontal Minimum Search, which are used to simplify and accelerate motion estimation in video processing. Currently, most video encoders use partial motion estimation because full motion estimation is incredibly expensive – it requires a massive number of sum of absolute difference (SAD) calculations to achieve a good result.
Without SSE4 there are a large number of calculations going on, including absolute values, subtractions and additions to properly estimate motion during the encode. On the other hand, with SSE4.1 you need a single instruction to cover the entire function. Additionally, developers will probably want to find the best SAD – this can be done with just a single instruction in SSE4.1, while if you’re using existing scalar instructions, it requires a large number of branches to achieve the same result.
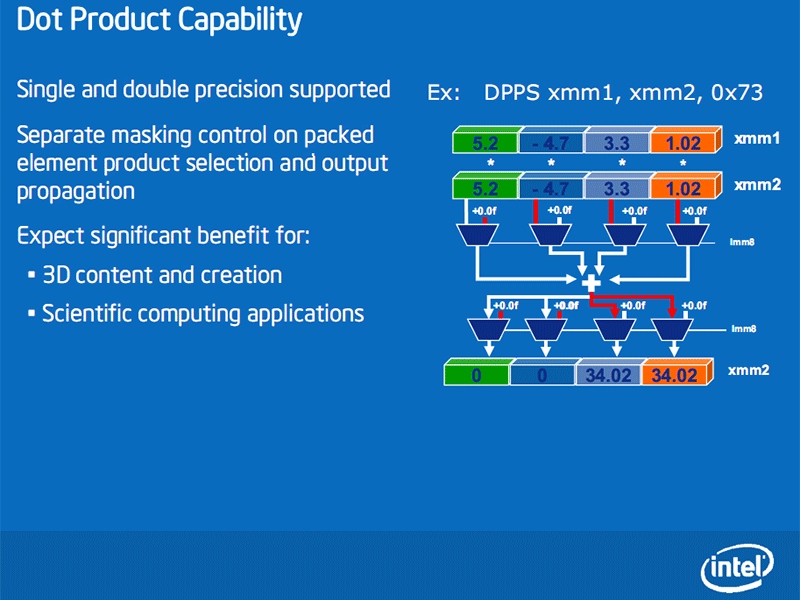
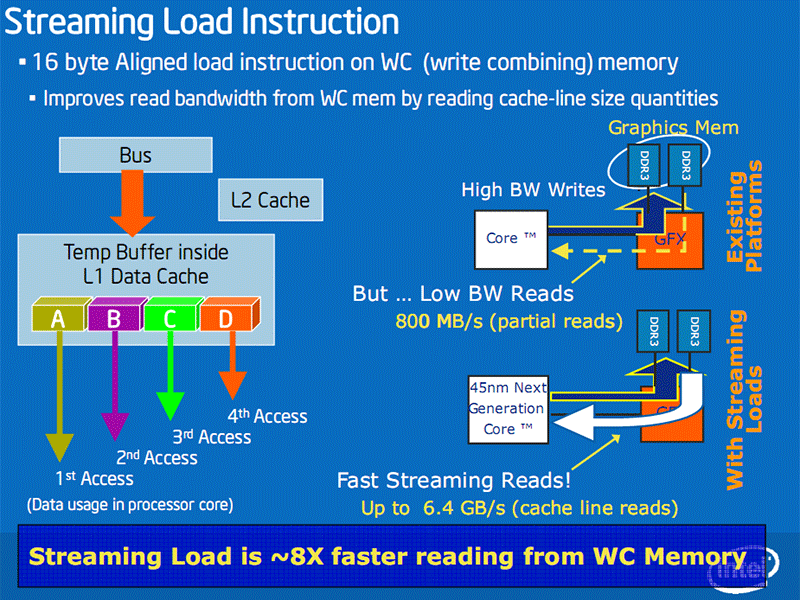

Most of the other new instructions in SSE4.1 are focused around video processing, multimedia and gaming, and also help to improve compiler vectorisation too, but the improvements in performance are more incremental than the Fast Block Difference and Horizontal Minimum Search instructions. Many are also to balance previous SSE advancements to make it easier to do the backward or alternative function to an existing one.
DivX 6.7 that makes use of this is already freely available, and other video encoding applications like the latest TMPEG (out in Japenese now, but English is due in a few weeks) also offers SSE4 enhancements. It'll likely be taken up in time, like all new SSE instruction sets - hopefully we'll see codecs like X.264, H.264 and XviD enhanced in the future for example.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.