
Native quad core versus “dual die” quad core.
Currently Intel’s quad core implementation relies on it having two Core 2 dies on a single package. It can easily pull this off because it doesn’t integrate the memory controller into the CPU. This allows more cores to be added as needed.However, this creates an inherent performance problem, since both die are only connected only through the CPU front side bus (FSB). Sending data from core one to three means that it has to be sent out of the CPU to the northbridge and then back again creating a massive additional latency and reducing the bandwidth available for memory access.
Discussion between cores one and two or three and four is okay, because they are on the same piece of silicon, but still 50% of the time there’s a latency problem.
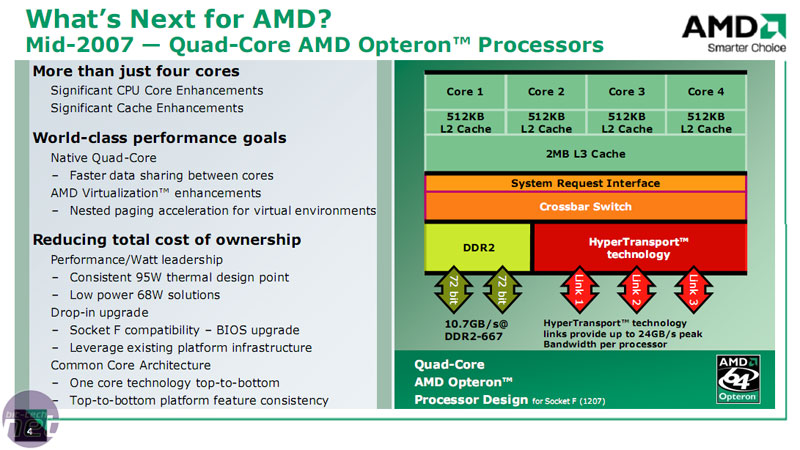
AMD may have stubbornly held out and waited on a native quad core design, but its designs are also limited by the fact the additional complexity of the integrated memory controller means you can’t just throw in another couple of cores. It requires specific optimisation for multi-core as well as redesigning the core silicon, a process that isn't quick.
AMD has designed the CPU so it has an ‘Internal System Request Queue Crossbar’ which allows each core to talk to each other, access memory or connect to other CPUs through HyperTransport. In this way, the cores don’t have to worry about the limitation of FSB bandwidth to talk to other CPUs, other cores or memory.

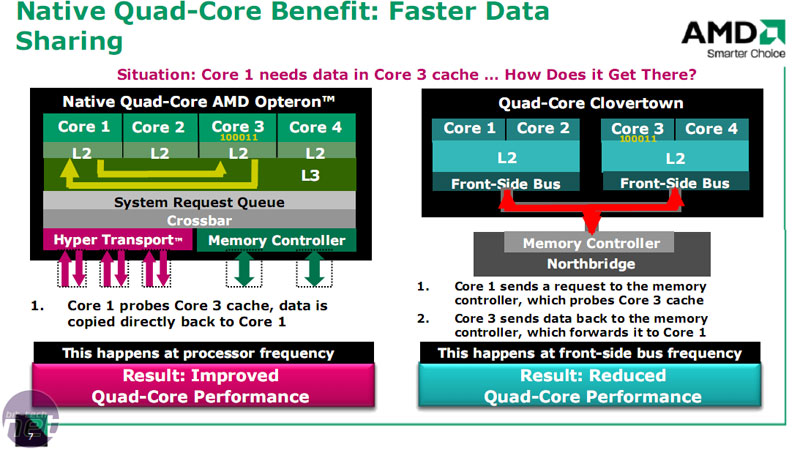
In contrast, AMD doesn't have the same problem so scaling by adding more cores works far better with HyperTransport, as each discrete CPU has its own memory to access. Ironically, AMD even has better memory performance even than Intel using DDR3 because of its integrated controller, although four cores now suffer longer queues for access. In this respect AMD has increased the native DDR2 speed support from 800MHz to 1066MHz, to help alleviate this issue.
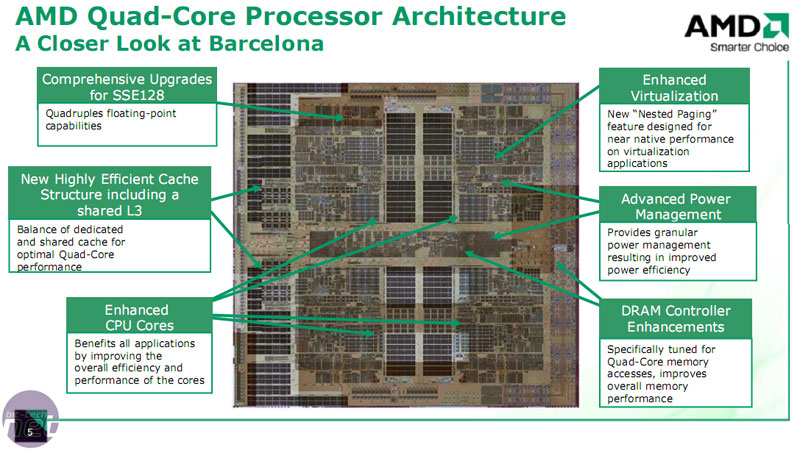
128-bit SSE with dedicated 36-bit floating point scheduler.
AMD has updated its SSE engine and committed a start-to-finish 128-bit SSE execution. Instruction fetch and L1 data cache bandwidth get upgrades to 128-bit to match the L2 cache and northbridge bandwidth. In comparison, Intel’s current quad core Clovertown only has a 64-bit instruction fetch and L1 data cache bandwidth which means Intel has to do twice as many clock cycles as AMD, for the same amount of work in this instance.There is also an updated 36-bit dedicated floating point operation scheduler, compared to Intel’s 32-bit shared integer and floating point operation scheduler. The heaviness of SSE requirement in the executing program will determine how much this affects performance.
SSE4 Instructions
Like Intel’s Penryn, AMD's quad core Opterons and Phenom will include the latest SSE multimedia instructions, so programs like of DivX 6.22 that support it will be accelerated.
RELATED ARTICLES






MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.