
Custom Filter Anti-aliasing:
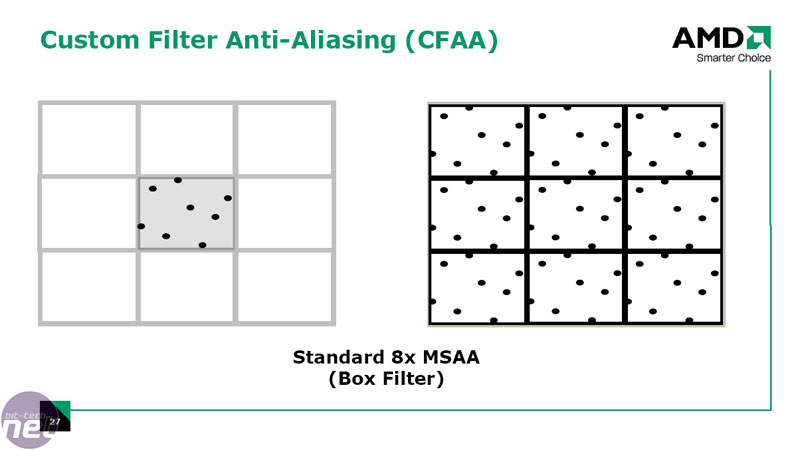
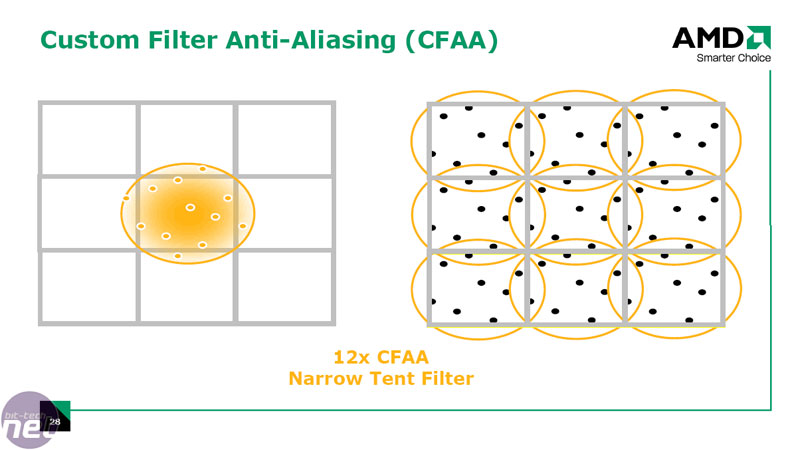
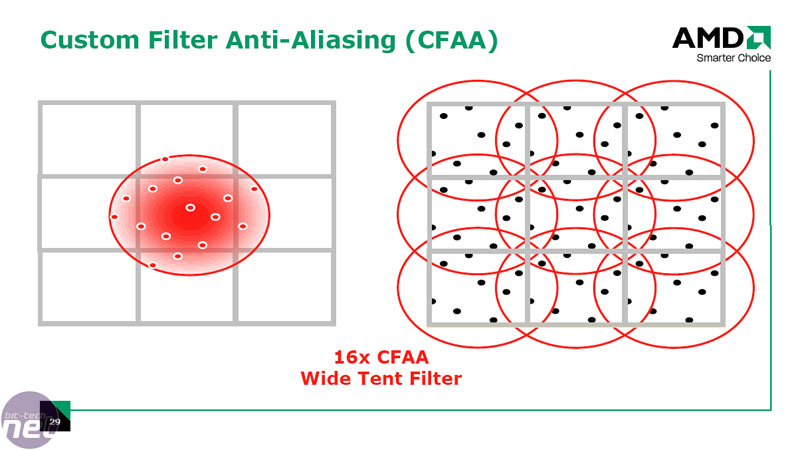
We briefly touched on AMD’s new Custom Filter Anti-aliasing technique on the previous page, but there’s a lot more to it than that. AMD says that because conventional anti-aliasing techniques rely on a standard box filtering sample method, there are a number of restrictions in place that result in diminishing returns at higher sample rates.In order to get around these constraints, AMD has implemented additional filters that sample outside the boundaries of the pixel being processed using non-uniform sample weights. The technique uses the shader units to perform the sample resolve pass on the un-sampled image and due to its programmable nature, the filters adapt to the characteristics of each pixel.
This technique has its benefits, with the main one being that you can take more samples per pixel without increasing the memory footprint required, but there are also some potential limitations too.
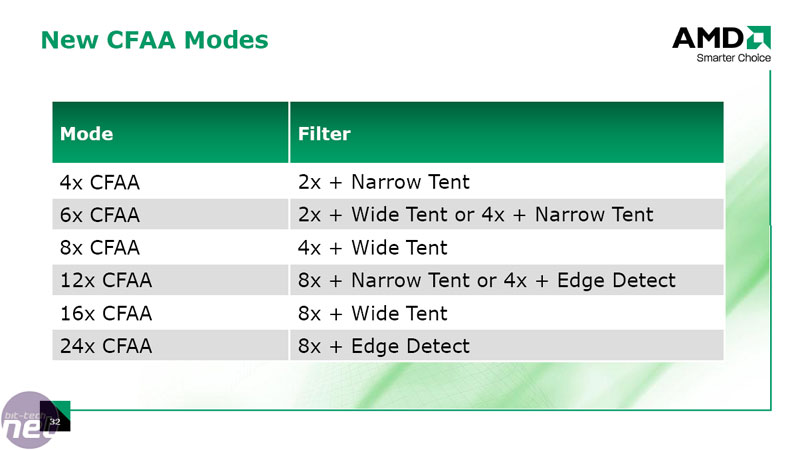
Edge detection works slightly differently to the tent filters, as it performs an edge detection (hence the name) pass back through the shader units using an even wider search around each pixel. This essentially means that pixels close to geometry edges are sampled at a higher rate than other pixels in the scene, meaning that it’s not too resource intensive. However, it does mean that there are a lot of calculations required to determine where the geometry edges are and also their orientation before it can sample.
The good thing though, is that these new anti-aliasing modes are software configured, meaning that it shouldn't be too hard to fix potential problems during AMD's monthly Catalyst driver release schedule.
Taking Ring Bus a step further...
With the Radeon X1000-series, ATI spent a lot of time talking about its new Ring Bus Memory Architecture and how it allowed for much more efficient memory allocation. The controller was called a Ring Bus because data travelled around two “rings” (which only handled reads) to four different stops each with two 32-bit memory channels attached to them. Write capabilities were still handled in the traditional way using a more conventional centralised crossbar switch.It’s fair to say that R600’s memory controller is an evolution of the one included in the X1000-series GPUs and it makes R600 the first GPU that features a 512-bit memory bus width. This means you can get more bandwidth from existing “mainstream” memory chips, and eventually it’ll deliver silly amounts of bandwidth with high speed GDDR4. In comparison, Nvidia's current flagship GeForce 8800 GTX has a 384-bit memory bus width with a 64-bit memory channel allocated to each ROP partition.
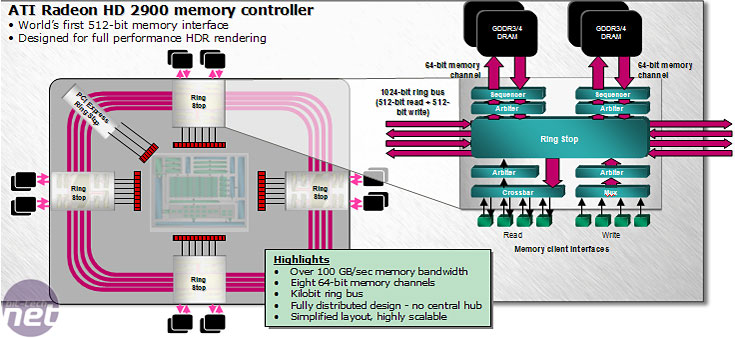
Internally, the ring bus has bi-directional 512-bit read and write rings so that the data can take the shortest possible route and each stop is connected to adjacent ring stops (one either side) via a 256-bit connection. Even the PCI-Express bus is treated as a ring stop this time around – it’s a source of more memory if the GPU requires it and is essentially an extension of HyperMemory. The DMA unit handles the traffic going across the PCI-Express bus in exactly the same way as it handles data going to and from local memory.
In total there are 84 read clients and 70 write clients spread across the rings. Inside the ring stops, both the read clients and the ring stop itself are connected to a crossbar, which then feeds data to an arbiter before either going back into the ring stop, or moving into local memory. The write clients send data to a multiplexer before forwarding onto the dedicated write arbiter.
The data keeps flowing until it finds the right ring stop which means that there is a potentially large latency problem. However, if you take the fact that there are many threads in flight at any one time into account, latency shouldn't be as much of an issue as it could be. Ultimately, bandwidth is more important than latency in this case, simply because of the amount of data that is flowing around the GPU at any one time – latency can be hidden with efficient scheduling and multiplexing, but a lack of bandwidth can't.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.