
Ultra Threaded Architecture:
Like ATI’s previous generation hardware, R600 is focused around ultra threading and the Ultra Threaded Dispatch Unit acts as the central point for R600. Let’s start at the top of the architecture and work our way through the chip...Command Processor:
The command processor is what gets the chip working on useful tasks, as it accepts the command stream from the graphics driver. It also performs state validation on code sent to the GPU too, ensuring the shader units are correctly configured before the data is sent to them. This helps to reduce CPU load, as code is validated before it gets to the setup engine.In the previous versions of DirectX, state validation was completed at the start of every loop through the GPU pipeline and was largely handled by the driver. This resulted in a large API overhead when the GPU is executing shader code many times over, because it had to keep re-validating its state. Of course, if you’re running applications based on DirectX 9 (and earlier), state validation will still be handled by the driver but some of the load will be offloaded onto the GPU’s dedicated silicon. AMD claims that the reduction in overhead could be as large as 30 percent in D3D9 applications.
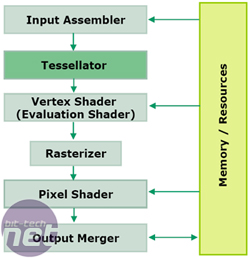
Setup Engine:
Once the code has been state validated, the Setup Engine can allocate the right resources to the shader programme, making sure the shader units are setup to receive either vertex, geometry or pixel shader instructions. The vertex assembler is responsible for arranging and storing vertex data optimally in memory. This is to make sure that fetching vertex data from local memory is not limited by available memory bandwidth.In addition, the vertex assembler is responsible for organising and feeding data into the programmable tessellation unit. This unit allows the developer to take a simply poly mesh and subdivide it using one of several subdivision surface types.
A vertex evaluation shader instruction is used to determine the maximum tessellation factor (which can be up to 15 times), meaning that there is no need for API support. The tessellator not only improves image quality by adding more detail into the scene, but it also can improve performance and conserve memory space by using a very low resolution model that’s sent through the tessellation unit to add more detail.
There are also assemblers for both geometry and pixel shader instructions too. The former handles either entire primitives or gathers the required data to generate new primitives, while the latter handles scan conversions, rasterization and interpolation. Data from the pixel shader assembler can be passed into the hierarchical-Z and stencil buffers for evaluation to determine whether or not the pixels will be visible. If they are not visible, the geometry is discarded before rasterization in order to make optimal use of the shader units – there’s no point processing a pixel if it’s never going to be displayed on screen.
Once the threads have been created by the Setup Engine, they’re submitted to the dispatch processor.
Ultra Threaded Dispatch Processor:
The dispatch processor is essentially R600’s scheduler – it determines where and when threads need to move to other parts of the GPU. There are command queues for each of the three different component assemblers (vertex, geometry and pixel) that fill with threads waiting for a free shader unit.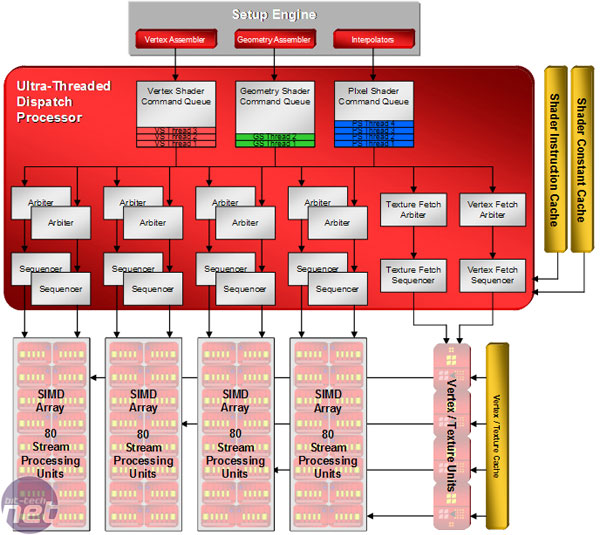
AMD says that hundreds of threads are in flight at any point in time, meaning that the threaded dispatch processor’s job is no mean feat. It has to make smart choices, as a wrong decision could potentially lead to a pipeline stall or an increase in latency, because an instruction is waiting for data from memory and holding up other instructions in the queue.
In order to combat this, the threaded dispatch processor can actually suspend instructions mid-flight if it’s waiting for data, allowing another thread to be processed with the smallest amount of latency possible. The suspended thread returns to its respective command queue to wait for the required data to arrive. Once the data has arrived, the thread can then continue its path through the shader clusters.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.