
GPU accelerated PhysX
Manju Hegde, former CEO of Ageia, a company that Nvidia recently acquired, talked about PhysX on the GPU. In just over three months, Ageia has ported the PhysX API to CUDA and released a public driver that enables GPU-accelerated PhysX – the actual port to CUDA took about a month.Hegde claimed that GPU-accelerated PhysX on the GeForce GTX 280 is around 15 times faster than the CPU for simulating fluids, 12 and 13 times faster at simulating soft bodies and cloth respectively.
He also said that in the first month following the Nvidia acquisition, more than 12 AAA titles were signed up to use PhysX – in comparison, Ageia managed to sign just two big titles in its two and a half year lifetime as a private entity.
Of the titles making use of PhysX, the most compelling demos we have seen were of DICE's Mirror's Edge, Backbreaker by Natural Motion and the remake of Bionic Commando, which is being developed by GRiN.
Hegde went onto talk about creating a scalable physics using a platform, known as APEX, that his team is working on. This will allow developers to drop physics effects into their game engines with a minimal amount of effort and, what's more, it'll automatically scale the simulation quality depending on what hardware is available in the system.
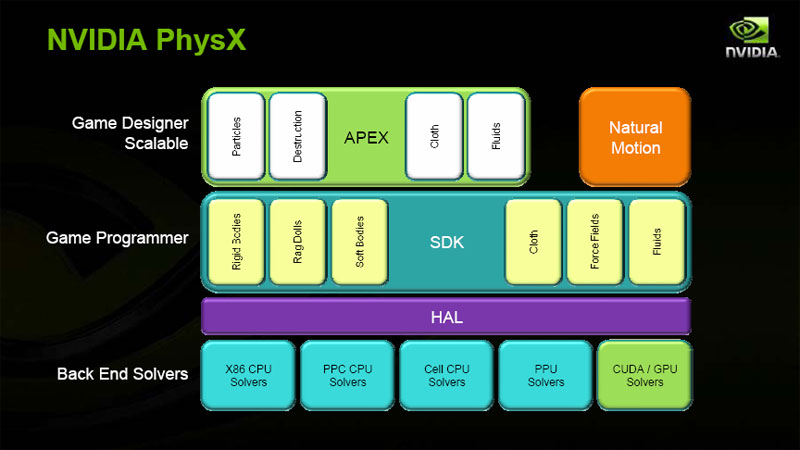
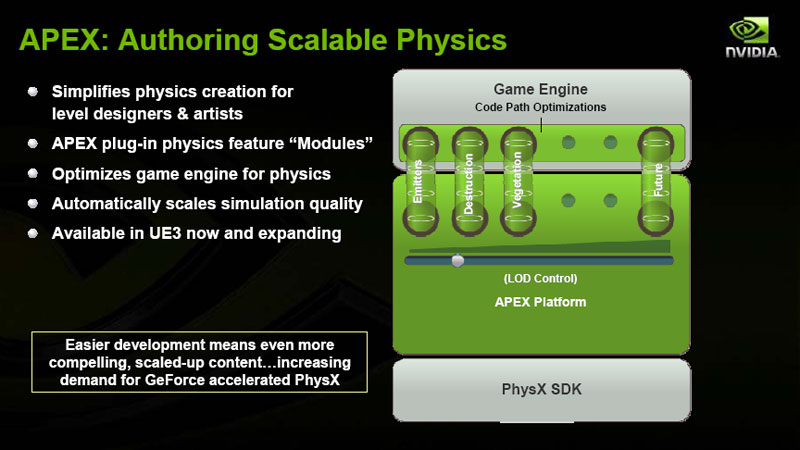
Click to enlarge
Our concerns for CUDA (and PhysX)
While this is all well and good, I have some concerns about PhysX – some of which are related to the recent developments in AMD's camp. After all, AMD has just announced that it plans to support and eventually GPU-accelerate Havok Physics. Now, let's put which API is better aside for one moment because, as a consumer, I really don't care what API is running the in-game physics as long as I can get a similar experience with competing hardware.Since AMD hasn't announced support for GPU-accelerated PhysX, and by the same token, Nvidia hasn't announced that it's working with Havok to accelerate Havok Physics on GeForce, we're in a bit of an unfortunate situation for gamers. One that reminds me of the days before pervasive 3D graphics APIs, where developers would develop games for certain hardware – and anyone that didn't own that hardware couldn't play the game.
While things aren't going to get that bad in this situation, we're going to have a scenario where, depending on a developer's allegiance (or the amount of money being thrown in the direction of their publisher), you'll probably get a significantly better experience if you've got the 'right' graphics card in your system. By that I'm not referring to the amount of money you've spent on your graphics card, I'm referring to who manufactures it (i.e. AMD or Nvidia).
That's not good for gamers, no matter how nice the physics effects look on the supported hardware – what we need is an industry standard for physics that all hardware vendors support. If that's PhysX or Havok (or both), that's great, as long as every hardware vendor has the opportunity to fully-accelerate the API in much the same way that they do with DirectX and OpenGL.
And speaking of OpenGL, Apple, in conjunction with a number of other industry partners—including both AMD, Intel and Nvidia—announced OpenCL (or Open Compute Language) support in OSX 10.6 Snow Leopard.
I spoke to Nvidia about its feelings towards OpenCL and I got a rather interesting, but slightly puzzling response:
- "CUDA is a highly tuned programming environment and architecture that includes compilers, software tools, and an API. For us, OpenCL is another API that is an entry point into the CUDA parallel-programming architecture. Programmers will use the same mindset and parallel programming strategy for both OpenCL and CUDA. They are very similar in their syntax, but OpenCL will be more aligned with OS X while CUDA is a based on standard C for a variety of platforms. We have designed our software stack so that to our hardware, OpenCL and CUDA code look the same. They are simply two different paths toward GPU-accelerated code.
"The CUDA and OpenCL APIs differ so code is not 100 percent compatible. However, they share similar constructs for defining data parallelism so the codes will be very similar and the porting efforts will be minor. The fact that CUDA is available today and is supported across all major operating systems, including OS X, means that developers have a stable, pervasive environment for developing gigaflop GPU applications now, that can be easily integrated with OS X via OpenCL when it is released.
"OpenCL actually utilizes the CUDA driver stack in order to deliver great performance on Nvidia GPUs. In the processor market, there are many different types of tools and languages. The parallel computing market will evolve similarly with many different types of tools. The developer gets to choose the development tools that best fills their needs."
No matter how much potential CUDA has, it's only supported by one hardware vendor and based on what I've heard from various sources, that's unlikely to change any time soon. After some long discussions, I did eventually get Nvidia to admit that it does see an industry standard taking over from CUDA in the future, but it is using CUDA to raise the awareness of GPU computing.
I guess that's fair enough and I hope OpenCL becomes a standard that's adopted by all parties – the good thing is that AMD has said its GPUs fully support the API as well, so we're moving in the right direction. Now all we need is for the API to be made available on all platforms and for both PhysX and Havok to be ported to it – at that point, our concerns with GPU-accelerated physics (and GPU computing in general) will have been addressed.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.