
Nvidia has thus far announced three separate Turing GPUs: The current flagship TU102 (shown below), which features in the RTX 2080 Ti; TU104, found in the RTX 2080; and TU106, which comes in the RTX 2070. Only the RTX 2070 features a fully enabled part; the RTX 2080 Ti and RTX 2080 have a few bits disabled, with fully enabled GPUs reserved for Quadro cards. As usual, the building blocks that we’ll move through are the same in each, so they all share the same benefits and features of the new design. All three are fabricated on the 12nm FFN (FinFET Nvidia) process from TSMC, although density is roughly on par with the 16nm Pascal chips. Excluding AI and ray tracing workloads, the push with Turing is on performance more than it is efficiency, and at the heart of improved performance is a redesign of the Streaming Multiprocessor (SM).
There are high-level similarities to Pascal GPUs that up-to-date gamers will be familiar with. The GPUs are still divided into Graphics Processing Clusters (GPCs) which sport a Raster Engine linked to a series of Texture Processing Clusters (TPCs), inside which are the SMs, and that’s where the differences start.
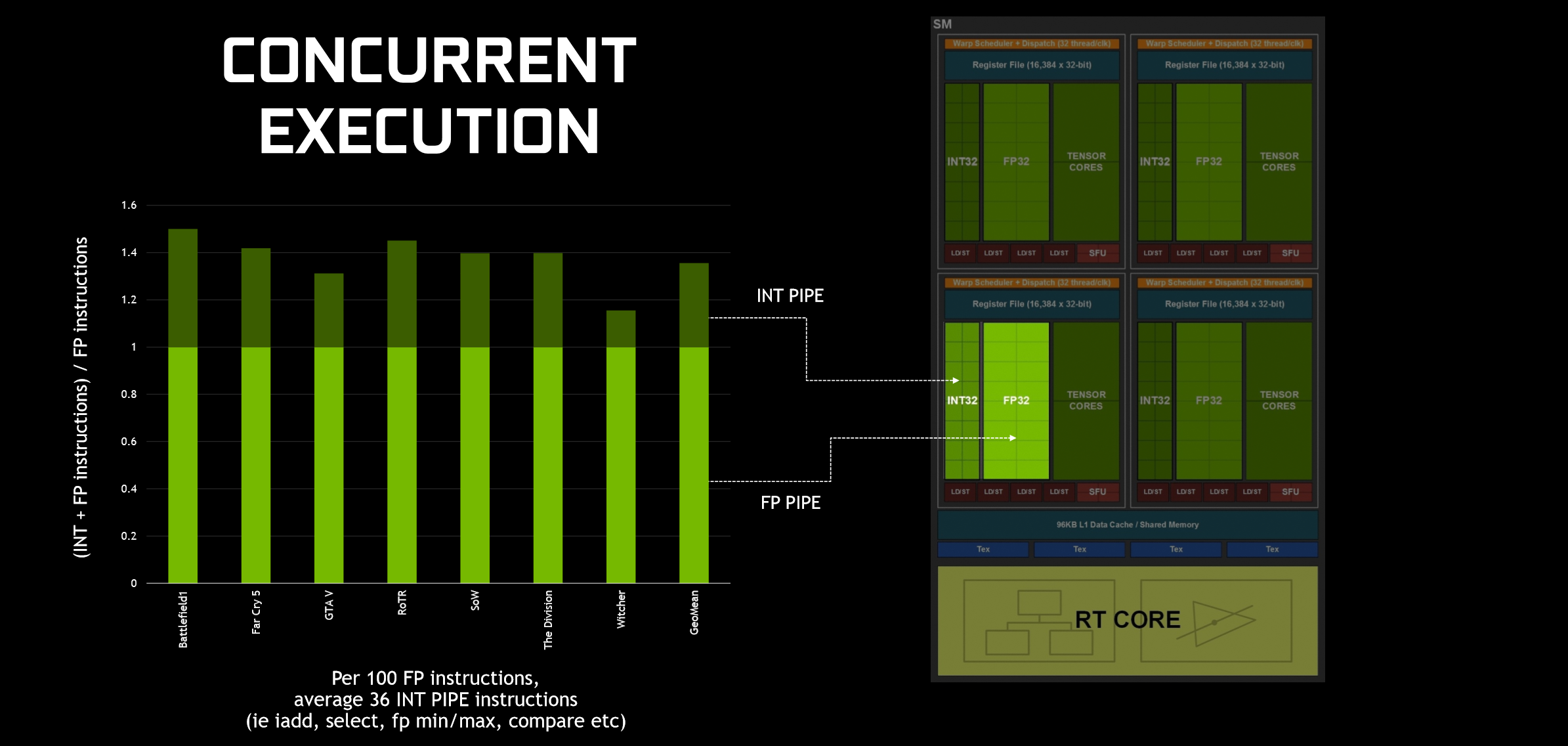
In an analysis of ‘several modern applications’ (gaming), Nvidia claims to have found that for every 100 floating point instructions (the most common in graphics shader workloads), there would be on average 36 simpler integer instructions that also needed computing. Previous SM designs were forced to run both types along the same datapath, meaning that integer instructions halted the queue of floating point ones. In Turing, Nvidia has created a completely separate and independent datapath for integer math by including an integer core (INT32) for every standard floating point CUDA (FP32) core. Since instructions can be executed at the same time along these different paths (Concurrent Execution), effective floating point throughput is boosted by 36 percent (using Nvidia’s analysis). This is a workload-dependent boost, however, so we can expect variation based on the game.
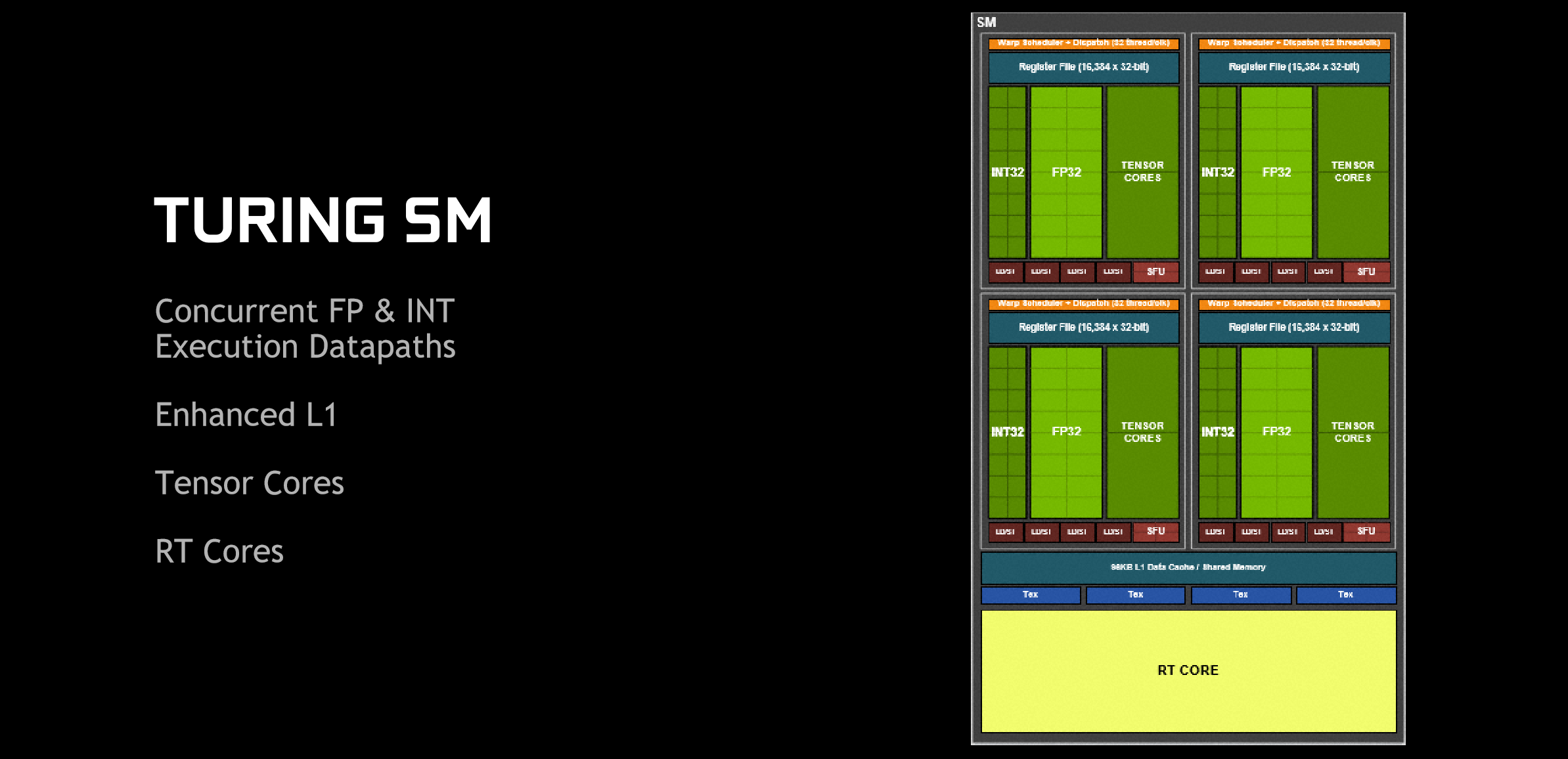
Previously, each SM had 128 FP32 cores (four blocks of 32), but now each has 64 FP32 cores and 64 INT32 cores, divided into four equal blocks where each block also has its own 64KB register file, two Tensor Cores (more on those soon), and a new Warp Scheduler that can dispatch to both types of core at once i.e. up to 32 threads per clock cycle per SM. Each SM also gets its own RT Core (more on these also coming soon) and four Texture Units (TUs). By having two SMs per TPC instead of one like before, the FP32 CUDA Core count and TU count are the same at the TPC level as before.
It's worth noting that a couple of FP64 units are also included in each SM (not shown in the block diagram) in order to ensure that any FP64 code can actually run. These double-precision cores run at 1/32 the speed of the regular single-precision cores.
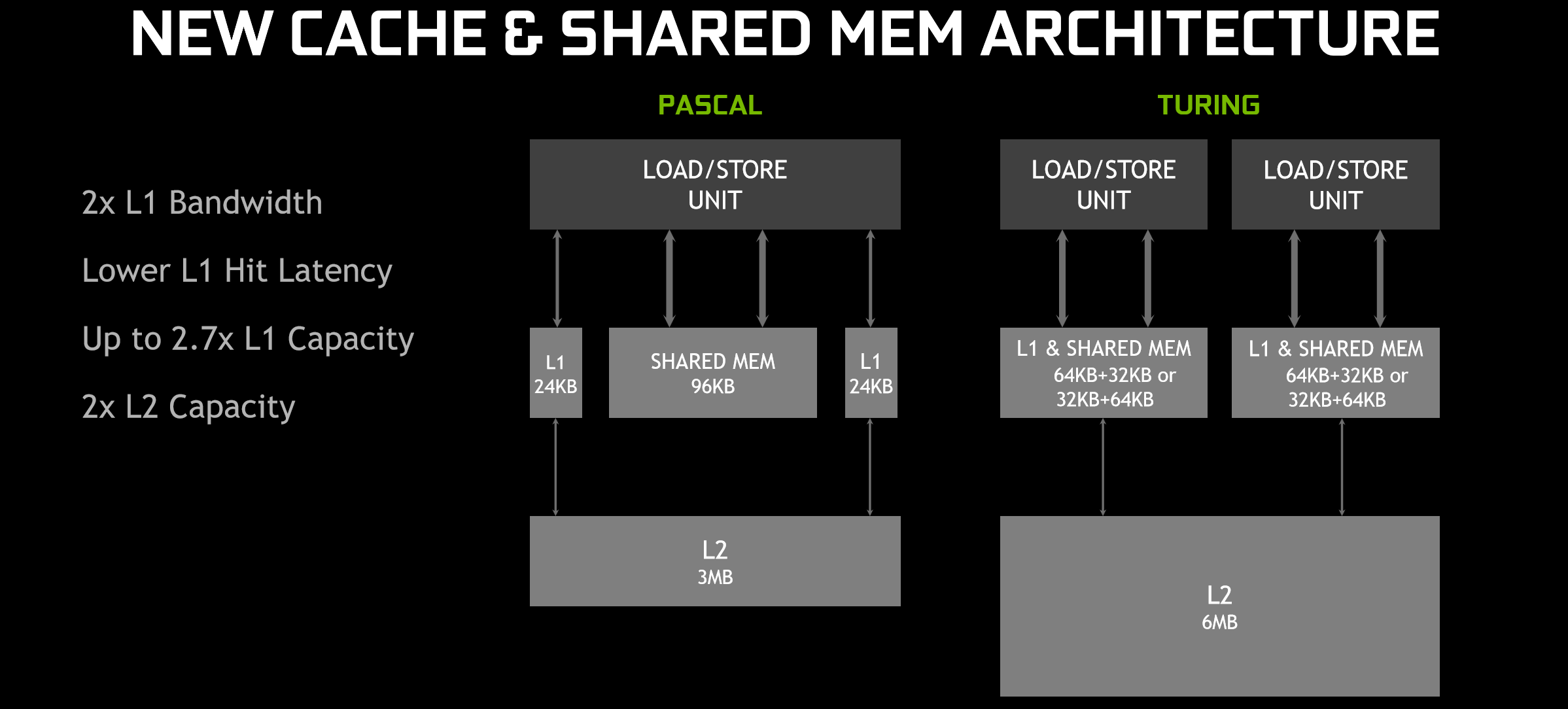
The second major change is to do with the memory. The previous SM had 48KB of L1 memory and 96KB of shared memory per SM (and thus per TPC), but Turing introduces a new unified architecture for these functions, with 96KB available per SM (192KB per TPC). This can be configured to 64KB L1/32KB shared or 32KB L1/64KB shared. L1 capacity thus increases per TPC by between 1.3x and 2.7x, and Nvidia says there are L1 bandwidth and latency improvements in the new design too, since L1 latches onto the benefit of traditional shared memory being closer to the cores. We’re also told that the new design means less work required on the developer side to attain maximum performance.
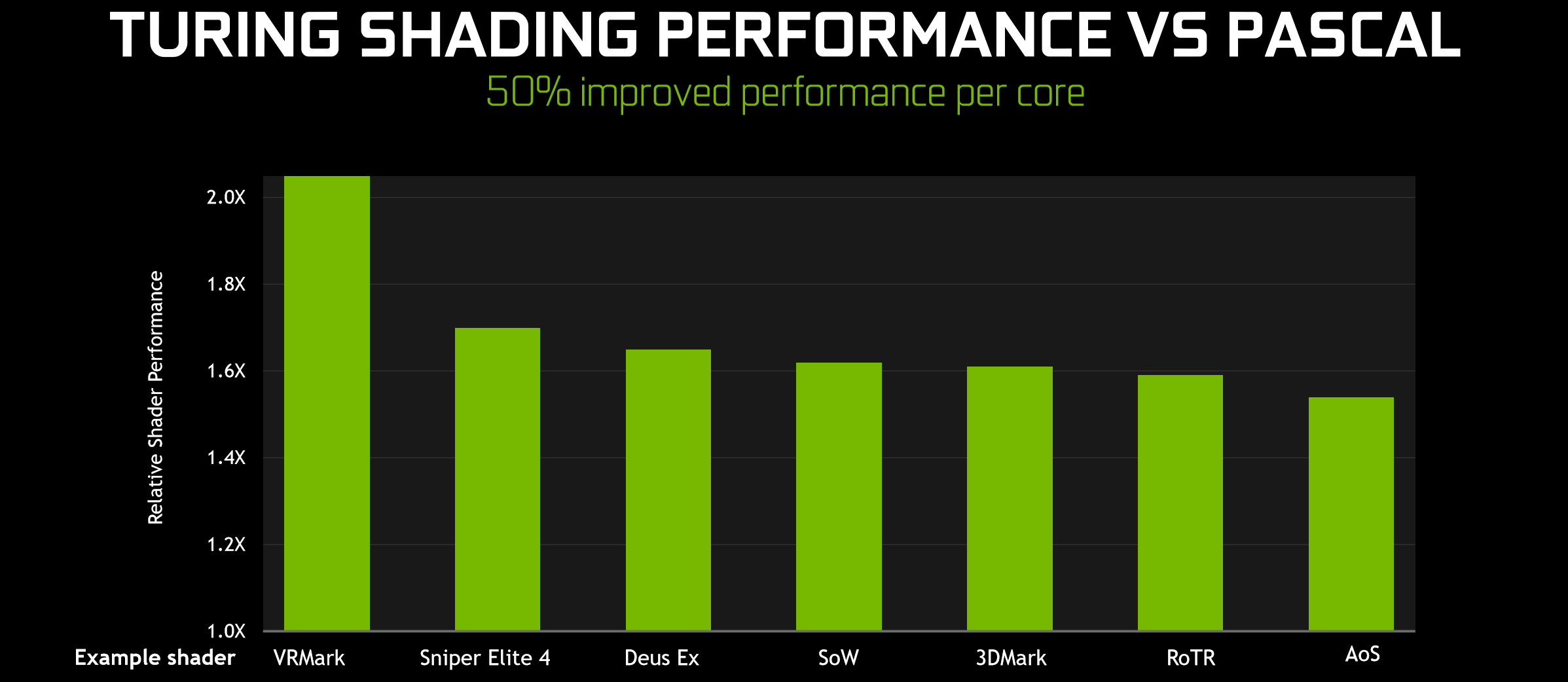
Overall, Nvidia reckons it can achieve an average of 50 percent more performance per CUDA core. That’s a nice figure, of course, but there’s not a great deal of information indicating the variability around this mean. Importantly, the improvements mean that any workload that doesn’t leverage the new AI or ray tracing capabilities (pretty much everything at the moment) should see some benefit from the Turing architecture, but how much remains to be seen, and it could vary more than you might be used to.
Faster cores aren’t going to be much use if the GPUs are bottlenecked by memory performance. Which brings us to…







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.