
AMD has unveiled some new details about its Flex FP floating-point unit, due to début with the Bulldozer processor line, due for servers and workstations next year.
In a blog post entitled The New Flex FP, AMD's director of product marketing John Fruehe explains that the new hardware 'delivers tremendous floating-point capabilities for technical and financial applications,' offering much improved performance and flexibility over the company's older floating point units.
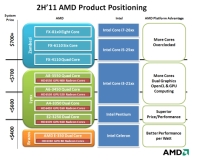
Fruehe states that a single Flex FP will be shared between every two cores, so the company's Interlagos 16-core processors will include eight Flex FP units, which are capable of executing 256-bit floating-point commands through the AVX instruction set extension. Remember that Bulldozer uses a dual-thread design similar to Intel's Hyper-Threading - see the above Bulldozer link for more on this.
Although Fruehe admits that there is 'no such thing as a 256-bit command,' Fruehe explains that AVX-compatible code will be able to 'execute eight 32-bit commands or four 64-bit commands per cycle,' double that of traditional 128-bit floating-point units.
Code doesn't have to be rewritten to support AVX in order to take advantage of the Flex FP, however. The Flex FP is comprised of two 128-bit FMAC units capable of performing FMAC, FADD, or FMUL instructions per cycle, either combined as a 256-bit instruction or split as two 128-bit instructions, which apparently provides significantly higher performance than 'competing solutions.'
Despite the improvements offered by the Flex FP hardware to unoptimised code, Fruehe admits that 'there are benefits of recompiled code that will support the new AVX instructions,' but he appears confident that despite not expecting to see 'rapid movement to AVX until well after the platforms are available on the streets' the new Flex FP will provide significantly improved performance and flexibility from day one.
Do you think that Bulldozer will be the server-room winner that AMD expects, or is it going to take more than a more flexible floating-point unit to out-muscle Nehalem-based Xeons? Share your thoughts over in the forums.
In a blog post entitled The New Flex FP, AMD's director of product marketing John Fruehe explains that the new hardware 'delivers tremendous floating-point capabilities for technical and financial applications,' offering much improved performance and flexibility over the company's older floating point units.
Fruehe states that a single Flex FP will be shared between every two cores, so the company's Interlagos 16-core processors will include eight Flex FP units, which are capable of executing 256-bit floating-point commands through the AVX instruction set extension. Remember that Bulldozer uses a dual-thread design similar to Intel's Hyper-Threading - see the above Bulldozer link for more on this.
Although Fruehe admits that there is 'no such thing as a 256-bit command,' Fruehe explains that AVX-compatible code will be able to 'execute eight 32-bit commands or four 64-bit commands per cycle,' double that of traditional 128-bit floating-point units.
Code doesn't have to be rewritten to support AVX in order to take advantage of the Flex FP, however. The Flex FP is comprised of two 128-bit FMAC units capable of performing FMAC, FADD, or FMUL instructions per cycle, either combined as a 256-bit instruction or split as two 128-bit instructions, which apparently provides significantly higher performance than 'competing solutions.'
Despite the improvements offered by the Flex FP hardware to unoptimised code, Fruehe admits that 'there are benefits of recompiled code that will support the new AVX instructions,' but he appears confident that despite not expecting to see 'rapid movement to AVX until well after the platforms are available on the streets' the new Flex FP will provide significantly improved performance and flexibility from day one.
Do you think that Bulldozer will be the server-room winner that AMD expects, or is it going to take more than a more flexible floating-point unit to out-muscle Nehalem-based Xeons? Share your thoughts over in the forums.
RELATED ARTICLES





MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04


Want to comment? Please log in.